Data Glossaries: The Semantic Layer That Decides Whether AI on Your Data Actually Works
A follow-up to Data Catalog Core Concepts Explained.
In the previous post I argued that a weak glossary is the single biggest reason data catalogs become ghost towns. I want to take that claim seriously, because I keep watching teams nod at it, agree that glossaries matter, and then ship a catalog where the glossary is a folder of thirty terms named after database columns with the descriptions left blank.
There's a deeper reason this keeps happening. The data engineering profession learned how to model schemas, how to wire pipelines, how to write tests, how to draw lineage. It did not, as a discipline, learn how to model meaning. That work belongs to a different field entirely (information science), and most data teams have never been exposed to it.
This post tries to close that gap. It's a deep dive on data glossaries: what they actually are (and aren't), the three structural types you can build them as, what each one buys you, how to start without drowning, and what a realistic 12-month roadmap looks like. I'll keep referring back to the catalog post where the concepts connect.
If you're standing up a catalog in 2026 and you're serious about AI agents using it, glossary work is no longer optional. It's the layer the agents will lean on hardest, and the layer that's hardest to fake.
The "active customer" problem
Before getting to definitions, the pain.
Pick any business term that matters in your company. "Active customer." "Monthly recurring revenue." "Churn." "Lead." "Inventory." Ask five people in five different departments to define it precisely, including the exact filter logic. Write down the answers.
You'll get five answers. They will not match.
Finance counts an active customer as one with a billable event in the last 30 days. Product counts one with a session in the last 14. Marketing counts one who opened an email in the last 90. The customer success team has a fourth definition involving health scores. Sales has a fifth, which is whatever their CRM is configured to show this quarter.

All five teams are correct, given the question they're trying to answer. None of them know the others have different definitions. The dashboard executives look at to decide whether the business is healthy averages across these five definitions without anyone realizing.
Now drop an LLM into this. Connect Claude or ChatGPT to the warehouse with read access. Ask it: "How many active customers do we have?" It will write a SQL query against whichever active_customer view it found first. It will return a confident number. Nobody will know whose definition that number reflects, including the model.
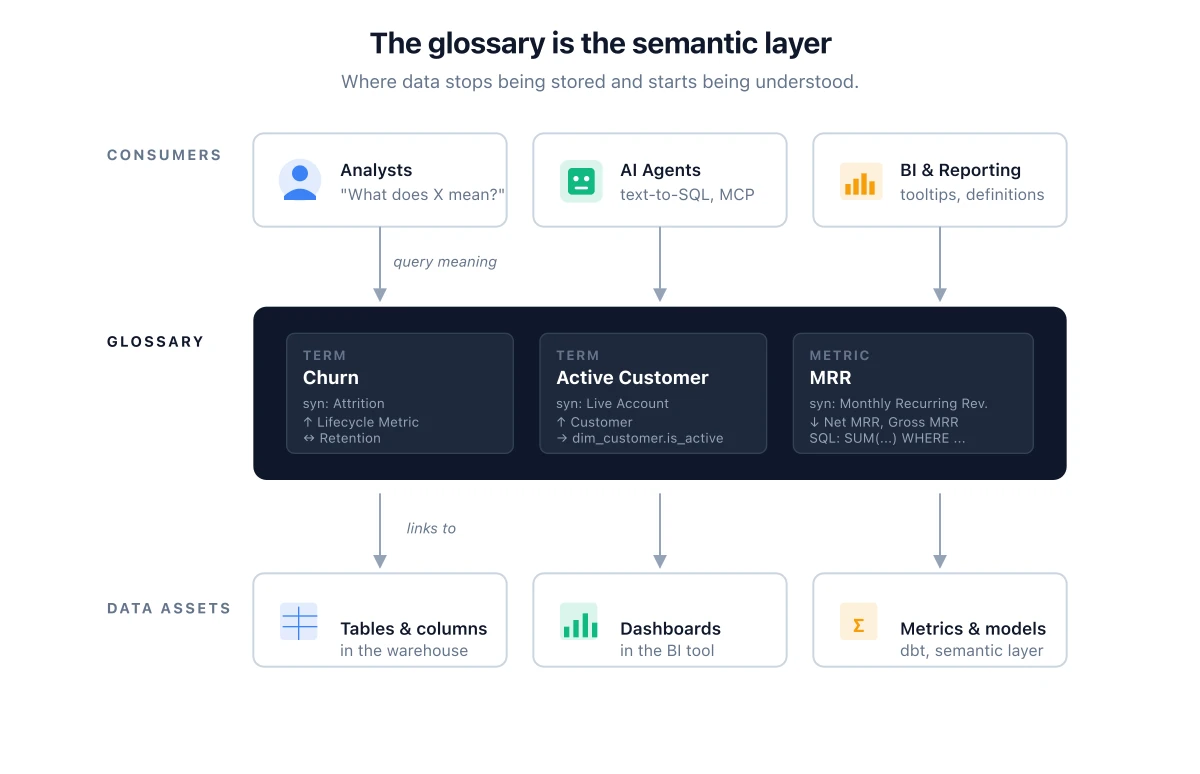
This is what a glossary exists to fix. Not by picking one definition and forcing the company to agree (which never works), but by making every definition explicit, attached to the assets that implement it, navigable through their relationships, and exposed to the systems that need to understand them: humans and AI agents alike.
A glossary, properly built, is the place where your data goes from stored to understood.
What a glossary actually is, and what it isn't
A data glossary is the controlled vocabulary of your business as it appears in your data. It's a structured set of glossary terms, where each term answers a single question: what does this word mean in this company, precisely, in business language. A glossary lives inside a data catalog (or alongside it), and its terms get linked to the assets (tables, columns, dashboards, metrics) that implement those concepts.
That's the definition. Now the four things a glossary is constantly confused with, because the confusion is the source of half the failed glossary projects I've seen.
A glossary is not a data dictionary. A data dictionary is a technical document, usually generated from schemas, that describes columns: name, type, nullability, sometimes a one-line comment. It's bound to a specific table in a specific system. A glossary is the layer above that: it describes what Customer means in the business, independently of the dozen tables across three warehouses that contain customer data. The dictionary tells you the column exists. The glossary tells you what the column is about.
A glossary is not a classification system. Classifications are labels for categorization: PII.Sensitive.Email, Tier.1, Confidentiality.Internal. They answer "what category does this asset fall into for policy purposes." Glossary terms answer "what does this concept mean." Both are useful, both live in the catalog, but they do different jobs. Classifications enforce policy. Glossary terms convey meaning. Mixing them up produces glossaries full of PII and Critical "terms," which is exactly the failure mode catalogs slip into when nobody on the team has internalized the distinction.
A glossary is not a schema. Schemas are structural; they say what fields exist and what types they are. Glossaries are semantic; they say what the fields mean. A column named cust_status_cd with type VARCHAR(2) is fully described by the schema. What cust_status_cd actually represents, what values it can take, what each value means for the business, that's glossary work.
A glossary is not an ontology. This is the most important distinction for anyone with a research background. An ontology is a formal, machine-reasoning-grade model of concepts and their relationships, usually expressed in RDF/OWL with logical axioms a reasoner can chain. Ontologies are powerful but expensive to build and even more expensive to maintain. A glossary is the practical 80% of an ontology: it captures preferred terms, synonyms, and relationships, but it doesn't try to be formally complete or reasoner-ready. You can grow a glossary into an ontology later if you genuinely need automated reasoning. Most companies don't. Don't start with an ontology; start with a glossary, and stop there unless a specific use case forces you upward.
What you're building, then, is a controlled vocabulary that sits between your business concepts and the data assets that implement them. The structure of that controlled vocabulary is the next thing to get right.
The three flavors of controlled vocabulary
There are exactly three ways to structure a controlled vocabulary, and the choice you make has cascading consequences. The framing here comes from information science (specifically, library and archival science, which has been thinking about this problem for roughly a hundred years longer than data engineering has). The original post mentioned the three types briefly. This is the long version.

Folksonomies: free tagging, no rules
A folksonomy is a flat, user-generated set of tags. There's no controlled list of approved tags. Anyone can add any tag to any asset. The same concept might be tagged customer, customers, cust, customer-data, customer_dim, and Customer (note the casing) in different places, by different people, in different weeks.
People hate folksonomies the moment they try to govern them, but folksonomies have a real virtue: they capture how people actually talk about the data. When an analyst tags something weekly-numbers because that's what their team calls it, that's a real signal about a real piece of shared vocabulary that the formal taxonomy probably misses.
The value of a folksonomy is discovery and signal, not structure. Treat it as an input layer that surfaces candidate terms you might want to formalize later, not as the glossary itself.
| When to use | When it hurts | |---|---| | Early-stage catalog with no glossary yet | Trying to govern or search rigorously | | Capturing how teams actually talk | Compliance, audit, regulatory use | | Bottom-up signal about which concepts matter | AI systems that need disambiguation |
Most modern catalogs let you have a folksonomy layer (free tags) running alongside a controlled glossary. That's the right setup. Use folksonomy tags to spot terms that need formalizing; promote the best of them into the real glossary.
Taxonomies: hierarchical and controlled
A taxonomy is a tree. Every term has exactly one parent (except the root). Children are kinds of their parent: Active Customer is a kind of Customer, Email Marketing Campaign is a kind of Marketing Campaign. Terms are controlled: there's a defined list, a process to add new ones, and stewards who approve changes.
Taxonomies are what most teams reach for when they finally decide to "do glossaries properly." That's fine for some glossary work and a trap for the rest.
What taxonomies are excellent at: classifications, regulated domains, and anything that needs a single source of truth with a clear hierarchy. Regulatory frameworks are taxonomies (GDPR data categories, HIPAA PHI types). Financial reporting standards are taxonomies. PII classifications are taxonomies. When you need every asset to land in exactly one well-defined bucket, taxonomy is the right shape.
What taxonomies are bad at: business concepts that have synonyms, that overlap, or that exist in multiple parts of the business with slightly different shadings. Taxonomies force a parent-child relationship even when the real relationship is "these two terms are roughly the same" or "these two terms are related but neither contains the other." Try to model Customer, Account, Subscriber, and User as a pure taxonomy and you'll either invent a fake parent term nobody uses, or you'll force one of them to be a child of another in a way that contradicts how at least one team thinks about it.
| When to use | When it hurts | |---|---| | Classifications (PII, tier, confidentiality) | Concepts with strong synonyms | | Regulated reporting hierarchies | Cross-departmental shared vocabulary | | Domains where one canonical hierarchy exists | When relationships aren't strictly parent-child | | Asset categorization | When discovery requires finding "related" terms |
Taxonomies are a real and useful tool. They are not the whole story. The richer structure most glossary work actually needs is the third one.
Thesauri: clusters with three relationship types
A thesaurus is what library science settled on after a hundred years of trying to organize concepts for retrieval. It accepts the messy truth that vocabulary is not a tree, and gives you three explicit relationship types to model that mess.
Equivalent relationships (USE / UF). "Customer attrition" USE "Churn." The catalog knows that someone searching for "attrition" is looking for the same concept as "churn," and routes them to the preferred term. The reciprocal relationship is UF ("Used For"), meaning "Churn" UF "Customer attrition." One concept, many surface forms, one preferred label, and the search behaves intelligently across all of them.
Hierarchical relationships (BT / NT). "Broader Term" and "Narrower Term." Customer BT Active Customer. Marketing Campaign BT Email Campaign. This looks like a taxonomy and partially overlaps with one, but a thesaurus doesn't require strict tree shape. A term can have multiple broader terms (Email Campaign could be a narrower term of both Marketing Campaign and Direct Communication). The hierarchy is a graph, not a tree, which matches how concepts actually work in a real business.
Associative relationships (RT). "Related Term." Churn RT Retention. Revenue RT Cost of Goods Sold. Neither is broader or narrower than the other; neither is a synonym. They're concepts that someone looking at one will often need to know about the other. This is the relationship type that taxonomies cannot express at all, and it's the relationship type that powers the most useful discovery behavior in a glossary.
Why this matters concretely: an analyst searching for "customer churn" in a thesaurus-backed catalog can land on an asset tagged with the preferred term Churn, see that it's RT Retention, and discover the retention dashboard they didn't know existed. The model exposes the right adjacent concepts without anyone having to predict in advance which searches users would run.

| When to use | What it costs | |---|---| | Business concepts with synonyms (most of them) | More upfront design work | | Cross-domain discovery (the whole point of a catalog) | Stewardship effort to maintain | | AI systems that need to disambiguate | Tooling that can render the relationships | | Anywhere you want "related" suggestions | A bit of training for term authors |
For a serious data catalog glossary, the thesaurus is the target structure. Taxonomies are a special case of thesauri (a thesaurus with only hierarchical relationships). Folksonomies are a feeder layer underneath them. The richest catalogs implement glossaries as thesauri, expose taxonomies for classification work, and accept folksonomy tags as informal user input.
The anatomy of a glossary term
If a thesaurus is the structure, what does an individual entry inside it look like? The fields below are the union of what mature catalogs (OpenMetadata, Collibra, Atlan, Alation) carry. You don't need all of them on day one, but you should know what the full shape is before you start cutting.
Preferred label. The canonical name. One per term. Churn.
Definition. A single, unambiguous sentence in business language, written for a smart non-specialist. Not a database column description. Not a paragraph. One sentence that someone outside the team can understand without context. "The proportion of customers who end their subscription within a given time period."
Synonyms (alternate labels). All the other ways people refer to this concept. Attrition, customer loss, defection rate. These power equivalent-relationship search.
Broader terms. What this term is a kind of, or what concepts contain it. Customer Lifecycle Metric.
Narrower terms. What kinds of this term exist. Voluntary Churn, Involuntary Churn, Net Churn, Gross Churn.
Related terms. Concepts a reader of this term will frequently also need to understand. Retention, Customer Lifetime Value, Cohort.
Steward / owner. The single person (not a team) accountable for the definition. If three names sit here, it's owned by no one. This is the rule.
Reviewers. People who must approve changes. Stewards propose, reviewers ratify, the term changes.
Status. Draft, Proposed, Approved, Deprecated. The lifecycle (more on this below). Never Deleted.
Source of authority. Where the definition came from: a policy document, a financial standard, a board-approved metric definition. If a regulator audits you, this is the field they'll look at.
Examples. Concrete instances. For Churn, an example might be: "A customer on the monthly Pro plan who cancels their subscription on May 14th counts toward May's churn. A customer who downgrades to a cheaper plan does not."
Linked assets. The tables, columns, dashboards, metrics, and reports that implement this term. This is the field that makes the glossary actually useful in a catalog; without it, the glossary is just a fancy Wiki.
Implementation logic (optional but powerful). Where the term has an exact computational definition, the formula or SQL fragment that computes it. "COUNT(DISTINCT customer_id) WHERE subscription_end_date BETWEEN <start> AND <end>) / COUNT(DISTINCT customer_id) WHERE subscription_active_at(<start>)." Not every term needs this. Metrics do. Concepts don't.
The fields you actually invest effort in depend on the term's audience. A regulatory term needs a strong source of authority. A metric needs implementation logic. A cross-team shared concept (Customer) needs heavy synonyms and examples. Don't apply the same template to everything.
Glossaries in the age of AI agents
Everything above would be true in 2010. Two things have changed in 2026 that move glossary work from "good hygiene" to "you cannot ship AI on your data without it."

LLMs writing SQL need to know what your concepts mean. Without a glossary, an LLM asked "how many active customers do we have?" will pattern-match on column names and write a query against whichever table has the most plausible-looking schema. It will produce a number. The number will be wrong, or it will be right by accident, and there's no way to tell which without a human checking the SQL. With a glossary, the model can be given (via MCP, RAG, or a system prompt) the preferred definition of Active Customer, the exact table that implements it, the filter logic that defines membership, and the synonyms it might hear from a user. The query stops being a guess.
Semantic search lives or dies on glossary richness. Catalogs that have shipped vector-based semantic search (OpenMetadata 1.12 is the example I used in the previous post; the same is true of Collate, Atlan, and Alation) embed glossary terms alongside assets. A search for "customer attrition" doesn't need a literal string match against Churn if the glossary contains the synonym. The model's embedding for "attrition" is close to the embedding for "churn," and even closer when the term has been written with care. A glossary with 50 well-described terms produces dramatically better semantic search than a glossary with 500 terms named after database columns and left blank.
Disambiguation is the new requirement. When a user (or an agent) asks for "MRR," they could mean any of: monthly recurring revenue at billing, monthly recurring revenue net of refunds, monthly recurring revenue including expansion, or monthly recurring revenue as committed in contracts. Without a glossary, the system picks one (usually the first table it hits) and silently misleads. With a glossary, the term has narrower terms (Gross MRR, Net MRR, Committed MRR, Expansion MRR) and the system can either pick the right one based on context or ask. The cost of building these distinctions in the glossary is small. The cost of not building them, and shipping AI on top of the ambiguity, is operationally larger every quarter.
MCP exposes the glossary as a tool surface. With the catalog's MCP server running, any LLM client can call tools like list_glossary_terms, get_term, search_terms_semantically, and find_assets_linked_to_term. The glossary stops being a webpage people occasionally visit; it becomes a live API that agents query at decision time. This is what active metadata meant in the previous post, applied specifically to the semantic layer. The shift is from "the glossary is a reference doc" to "the glossary is a runtime dependency of every AI workflow."
The practical implication: every term you don't define is a place an agent will hallucinate. Glossary work is no longer just for the humans who couldn't find the right table. It's the substrate the agents reason on top of.
How to actually start
If you've read this far you might be thinking "great, my company has six hundred undefined terms, where do I begin." The honest answer is the same one I gave for domains in the previous post: not by trying to do everything. Glossary work that tries to cover the company on day one always fails. The work that succeeds is narrow, deep, and tied to a specific use case from the beginning.
The sequence that works:
1. Audit the painful terms first. Before writing a single definition, spend two weeks listening. Where do you see arguments about what something means? Which dashboards have multiple competing versions because no one could agree on the underlying metric? Which Slack threads have the phrase "wait, what do you mean by..."? Which onboarding decks have a definitions slide that contradicts a different team's definitions slide? Your first 20-50 terms are sitting in those conversations. Write them down. Don't define them yet; just inventory the conflicts.
2. Pick one domain. Use the domain model from the previous post. Whichever domain has the most painful definition problems, and whichever domain has at least one person willing to be a steward, is the right starting point. For most companies this is either Revenue / Finance (because money is involved and the conflicts have dollar costs) or Customer / Product (because the marketing/product/CS definition spread is widest). Don't start in a quiet domain. The discipline of glossary work needs immediate, visible payoff to survive.
3. Mine existing artifacts before writing anything new. Most of the definitions you need are already written, badly, in scattered places: dbt model documentation, dashboard descriptions, internal wikis, financial close documents, onboarding decks, contract appendices. Pull them all together. Reconcile the contradictions. The first version of most terms is a synthesis of three existing partial definitions plus a steward decision on which one wins.
4. Write definitions to a template. Every term in the pilot uses the same template (the anatomy section above gives you the fields). This sounds bureaucratic and isn't; it's the only way to enforce that someone writes the synonyms, the examples, the linked assets. Without a template, definitions degenerate into one-line sentences and the value of the glossary collapses.
5. Link to assets immediately. A term that isn't tied to at least one table, column, dashboard, or metric is a Wikipedia article living rent-free in your catalog. The link is what makes the term real. If you can't find an asset to link a term to, either the asset doesn't exist (which is interesting and probably a gap to fix) or the term isn't ready (which is fine; leave it Draft).
6. Get five real users dependent on it. The pilot domain isn't done when the terms are written. It's done when five specific analysts, PMs, or engineers can answer "where do I find the official definition of X" with "in the glossary" and mean it. That's the bar. If they still answer "by asking Sarah," the glossary hasn't landed yet.
7. Then, and only then, extend. Once the pilot domain works, the next domain is much cheaper because the patterns, templates, and stewardship rhythm are already established. Repeating the process domain by domain is sustainable. Trying to do all domains in parallel from day one isn't.
A reasonable first pilot covers 20-50 terms over 6-8 weeks, with one named steward, one reviewer, weekly office hours where any term can be discussed, and a public approval log. That's small enough to actually finish. Bigger than that is ambition; smaller than that is theater.
The lifecycle of a glossary term
Terms aren't static, and pretending they are is how glossaries drift into irrelevance. The lifecycle that holds up:
Draft. Anyone in the right domain can propose a draft term. Drafts are visible in the catalog but flagged. They don't count as official definitions.
Proposed. The draft has been written to the full template (definition, synonyms, examples, linked assets, steward identified). It's ready for review.
Approved. The reviewer has signed off. The term is now official. It appears in normal search results, can be linked from dashboards, can be referenced by agents.
Deprecated. The term still exists in the catalog but is marked as no longer authoritative. There's a pointer to the replacement term, if there is one. The history is preserved.
Never deleted. This is the rule that surprises people. Deleting a glossary term breaks every downstream reference: dashboards that linked to it, reports that cited it, AI conversations that grounded on it, audit trails that mentioned it. Deprecation preserves the audit trail and the reference integrity. Deletion destroys both. There is no business case for ever deleting a glossary term that has been Approved at any point.
Common pitfalls
The failure modes I see most often, in roughly the order they kill projects:
Boiling the ocean. Trying to define every term in the company before any term is usable. Glossary work has to compound from a working pilot. A 600-term glossary launched all at once is a 600-term glossary nobody trusts.
Stewardship vacuum. A glossary without a named steward per term is a glossary that drifts the moment the project sponsor moves on. A term owned by "the data team" is a term owned by nobody. Stewards must be named individuals with real accountability.
Definition by committee. Important terms tend to attract loud opinions. Every team wants a say. The solution isn't to refuse all the opinions, but to channel them through a clear process: stewards propose, reviewers approve, dissents are recorded but don't block. A term whose definition has been "in review" for three months is a term in a broken process.
Terms divorced from assets. A glossary that isn't linked to the tables and dashboards that implement it is a wiki. Wikis are fine. They're not glossaries. The link to assets is what makes the glossary load-bearing for both humans and AI.
No deprecation discipline. Terms get added easily and never removed. Three years in, the glossary contains seven versions of Active Customer from different reorgs, none of them clearly marked as current. The lifecycle has to be enforced.
One global owner. Centralizing all glossary stewardship in a single data governance team turns the catalog from a social network back into a bottleneck. The previous post made this point about catalogs in general; it's even more true of glossaries specifically. Distribute stewardship by domain.
Glossary as a one-off project. A glossary launched and then never maintained is worse than no glossary: it becomes confidently wrong as the business changes around it. The maintenance phase is not optional, and it has to be staffed.
Marketing writes the analytics definitions (or any equivalent ownership mismatch). The owner of a term has to be the team that actually uses it operationally. Definitions written by the team that talks about the data rather than the team that uses the data drift toward marketing copy and away from operational truth.
Treating glossaries and classifications as the same thing. They live in the same tool. They serve different jobs. Glossary terms convey meaning to readers; classifications enforce policy on assets. Conflating them produces a glossary full of PII and Tier 1 tags pretending to be concepts. Both are valuable; keep them separate.
Closing
The previous post argued that the conceptual model behind your catalog matters more than the tool you pick. The same applies a level deeper: inside that conceptual model, the glossary is the layer where data becomes meaning, and the structure you give the glossary determines whether that meaning is usable.
Folksonomies are a signal layer. Taxonomies are a classification layer. Thesauri are the structure that actually serves discovery, governance, and AI use in equal measure. The catalogs that get this right build glossaries as thesauri, link every term to the assets that implement it, run a real lifecycle, distribute stewardship by domain, and expose the whole thing as a runtime API that humans and agents both consult.
The catalogs that get it wrong publish a thirty-term glossary with one-line definitions and link it from the homepage and wonder why nobody uses it.
In 2026, with AI agents querying the catalog as a normal part of how they reason about your data, the gap between those two outcomes has become the gap between AI you can trust and AI that confidently produces the wrong number. The glossary is no longer a documentation artifact. It's a production dependency.
Start narrow. Pick one painful domain. Write twenty terms to a real template. Link them to real assets. Get five real users dependent on them. Then extend. The work is unglamorous and it compounds, same as everything else worth building in a data platform.
References
The thinking on controlled vocabularies in this post comes substantially from the same source I leaned on for the catalog post:
Olesen-Bagneux, Ole. The Enterprise Data Catalog: Improve Data Discovery, Ensure Data Governance, and Enable Innovation. O'Reilly Media, 2023. Chapters 5 and 6 are where the folksonomy / taxonomy / thesaurus framing lives, drawn from his information-science background. If you only read one thing on glossary structure, read those two chapters.
ISO 25964 ("Thesauri and interoperability with other vocabularies"). The international standard for how thesauri are structured, including the BT/NT/RT/USE/UF relationship types referenced above. Reading the standard directly is dry but unambiguous; it's the canonical source for the relationship semantics.
SKOS (Simple Knowledge Organization System), a W3C standard for expressing thesauri in RDF. If you ever need to make your glossary machine-readable in a portable format, this is what you'll convert to. Modern catalogs increasingly support SKOS import/export.
OpenMetadata glossary documentation at docs.open-metadata.org. The open-source implementation reference for everything in this post, including the lifecycle, the asset linking, the MCP exposure, and the related-term relationships.
The previous post in this series, Data Catalog Core Concepts Explained, sets up the catalog-level concepts (domains, lineage, active metadata) that this post builds on. Read them together; they're designed to.
Found this useful? Share it with someone who'd benefit. 🙏