A follow-up to Data Catalog Core Concepts Explained.
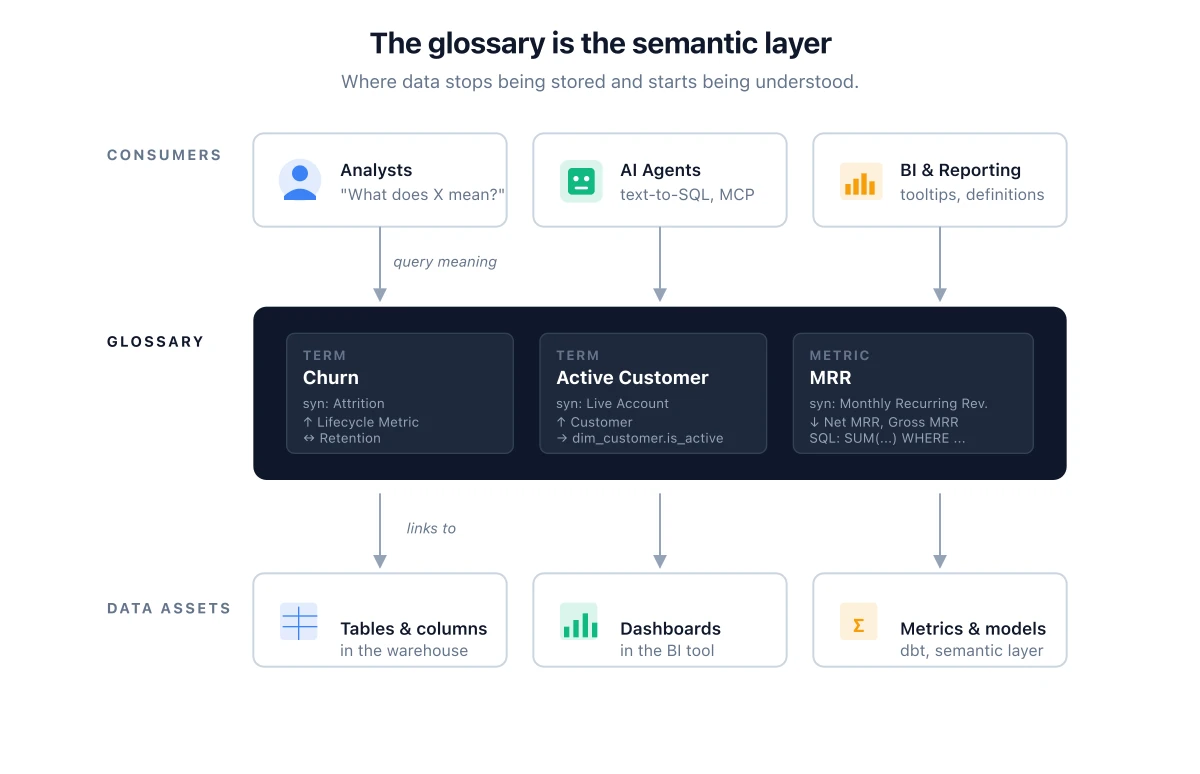
In the previous post I argued that a weak glossary is the single biggest reason data catalogs become ghost towns. I want to take that claim seriously, because I keep watching teams nod at it, agree that glossaries matter, and then ship a catalog where the glossary is a folder of thirty terms named after database columns with the descriptions left blank.
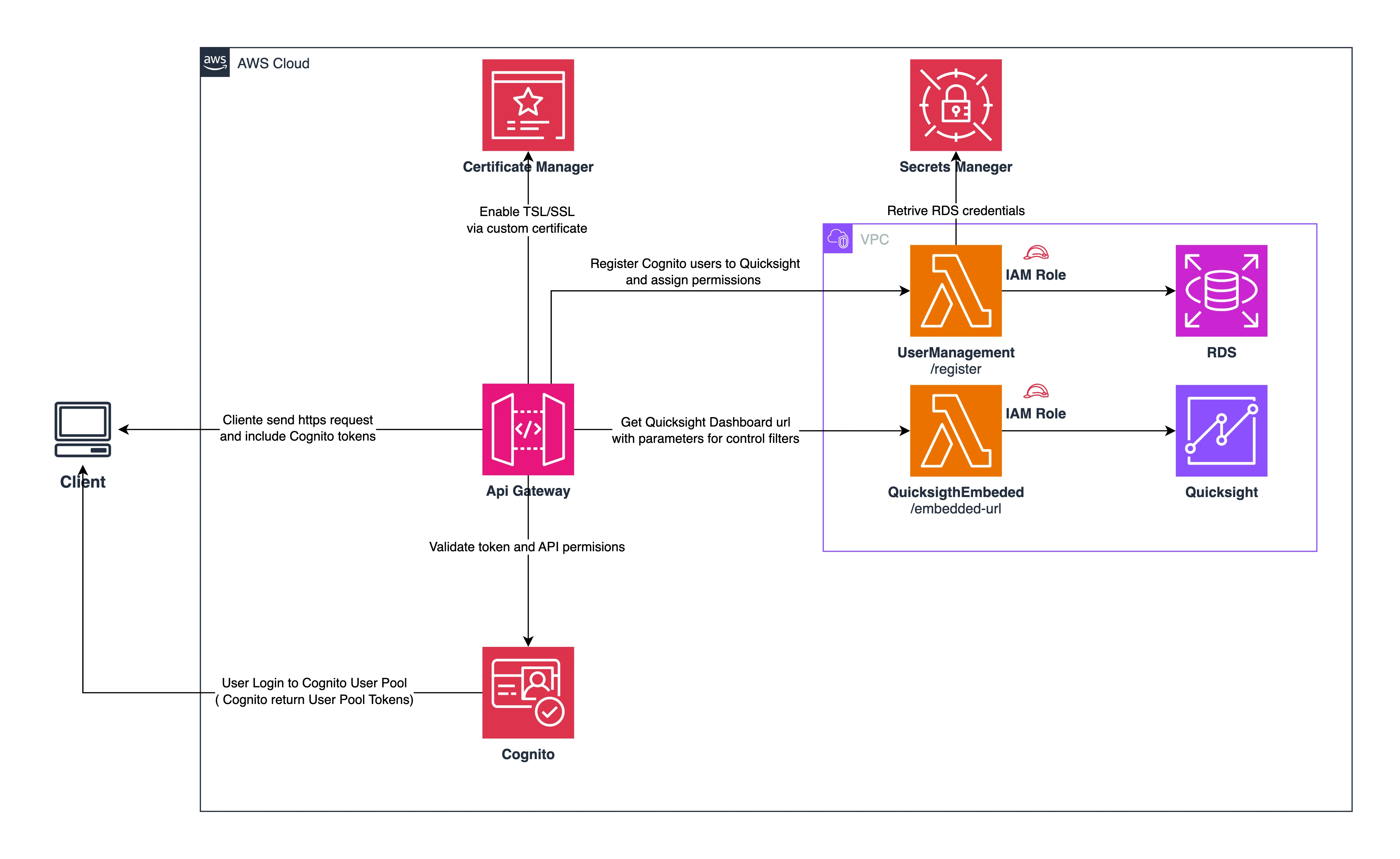
There's a deeper reason this keeps happening. The data engineering profession learned how to model schemas, how to wire pipelines, how to write tests, how to draw lineage. It did not, as a discipline, learn how to model meaning. That work belongs to a different field entirely (information science), and most data teams have never been exposed to it.
This post tries to close that gap. It's a deep dive on data glossaries: what they actually are (and aren't), the three structural types you can build them as, what each one buys you, how to start without drowning, and what a realistic 12-month roadmap looks like. I'll keep referring back to the catalog post where the concepts connect.
If you're standing up a catalog in 2026 and you're serious about AI agents using it, glossary work is no longer optional. It's the layer the agents will lean on hardest, and the layer that's hardest to fake.